

Azure Storage Tables can store tabular data at petabyte scale. Azure Queue storage is used to provide messaging between application components, as they can be de-coupled and scaled individually.
Azure Storage Tables
Azure Tables are a key-value database solution with rows and columns. Tables store data as a collection of entities where each entity has a property. Azure Tables can have up to 255 properties (columns in relational databases). The maximum entity size (row size in a relational database) is 1 MB.
Azure Tables organize data based on table name. For example, all customers should be stored in the Customers table whereas all products should be stored in the Products table.
The tables store the entities based on a partition key and a row key. All entities stored with the same partition key property are grouped into the same partition and are served by the same partition server. The developer has to choose a good partition key. Having a few partitions will improve scalability, as it will increase the number of partition servers handling a request.
Azure Storage Tables vs. Azure SQL Database
Microsoft Azure Tables does not enforce any schema for tables. It is the developer’s responsibility to enforce the schema on the client side. Azure Tables do not have stored procedures, triggers, indexes, constraints, default values and many more SQL Database features. The big advantage of Azure Tables is that you are not charged for compute resources for inserting, updating or retrieving data. You are only charged for the total storage you use. which makes it extremely affordable for large datasets. Azure Tables also scale very well without sacrificing performance
Using basic CRUD operations
This section will explain how to access table storage programmatically using C#. You can find the code for the following demo on GitHub.
Creating a table
- Create a new C# console application.
- Add the following code to your app.config file:

Setup the connection string to your storage account
Replace the placeholder with your storage account name and storage account key
- Install the WindowsAzure.Storage NuGet package.
- In the Main method, retrieve the connection string:

Retrieve the connection string
- With the following code can you create a table if it doesn’t exist:

Create the orders table if it does not exist
Inserting records
The following useful properties for adding entries to a table are provided by the Storage Client Library:
| Property | Description |
| Partition Key | The partition key is used to partition data across storage infrastructure |
| Row Key: | The row key is a unique identifier in a partition |
| Timestamp | Contains the time of the last update |
| ETag | The ETag is used internally to provide optimistic concurrency |
The combination of partition key and row key must be unique within the table. This combination is used for load balancing and scaling, as well as for querying and sorting entities.
To insert data into the previously created table, follow these steps:
- Add the following class:
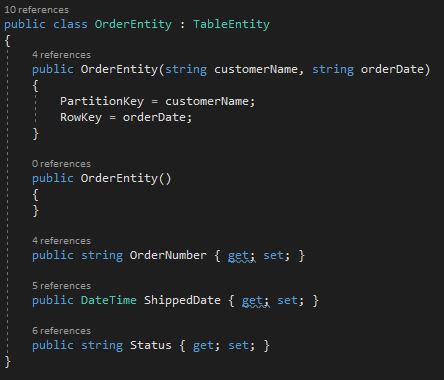
The OrderEntity class will be used to add orders into the table
- To add an order to the orders table, use the following code:
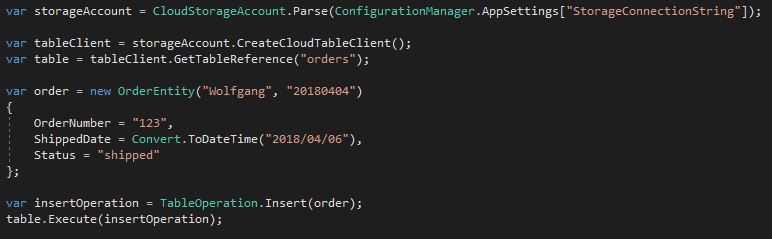
Insert a single record into the table
Insert multiple records in a transaction
You can group inserts and other operations into a single batch transaction. You can have up to 100 entities in a batch but the batch size can’t be greater than 4 MB.
To insert multiple orders in one transaction, add this code to your application:

Insert multiple records into the table
Getting records in a partition
You can select all entities in a partition or a range of entities by partition and row key. Wherever possible, you should try to query with the partition key and row key. Querying entities by other properties does not work well because it launches a scan of the entire table.
Within a table, entities are ordered within the partition key. Within a partition, entities are ordered by the row key. The RowKey property is a string, therefore sorting is handled as a string sort. If you are using a date value for your row key, as I did in the previous example, use the order year month day, for example, 20181220.
The following code gets all records within a partition using the PartitionKey property:
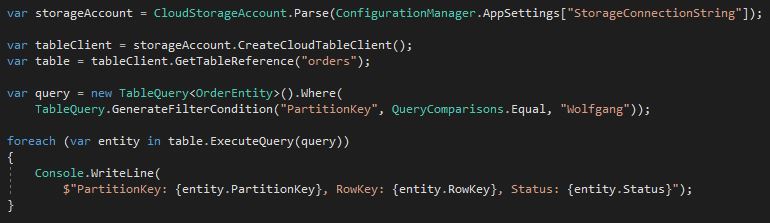
Retrieve all records of the table with the partition key Wolfgang
Updating records
To update records, you can use the InsertOrReplace() method. It creates a records if it does not exist and updates an existing one, based on the partition key and row key. Use the following code to do that:
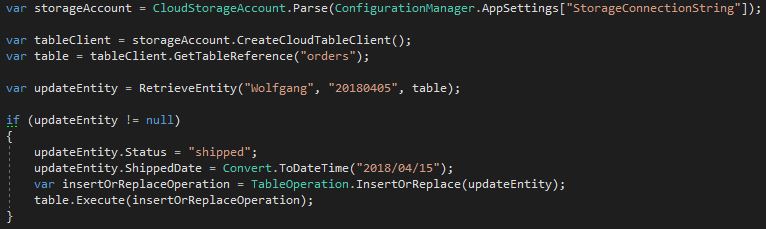
Update a record in the table
Deleting a record
To delete a record, you have to retrieve it first and then call the Delete() method. Use the following code to do that:

Delete a record from the table
Designing, managing, and scaling table partitions
As previously mentioned, tables are partitioned to allow massive scaling. The partition key is the unit of scale for storage tables. The table services will spread your table to multiple servers and key all rows with the same partition key co-located. Therefore, the partition key is an important grouping for querying and availability.
There are three types of partition keys:
| Partition Key | Description |
| Single Value | There is one partition key for the the entire table. This favors a small number of entities. It also makes batch transactions easier since batch transactions need to share a partition key. It does not scale well for large tables since all rows will be on the same partition server |
| Multiple Values | This might place each partition on its own partition server. If the partition size is smaller, it is easier for Azure to load balance partitions. Partitions might get slower as the number of entities increases. This might make further partitioning necessary at some point. |
| Unique values | This is for many small partitions. This is highly scalable, but batch transactions are not possible. |
For query performance, you should use the partition key and row key always together, if possible. This returns an exact row match. The next best thing is to have an exact partition match with a row range. It is best to avoid scanning the entire table.
Azure Storage Queues
Azure Storage Queue provides a mechanism for reliable inter-application-messaging to support asynchronous distributed application workflows.
Queues are often used in an ordering or booking application. The customer orders or books something, for example, a plane ticket and gets an email confirmation a couple minutes later. The order gets put into a queue at the end of the ordering process and then gets processed by a separate application. This takes sometimes more, sometimes less time, depending on the workload. After the order is processed, the customer gets an email confirmation.
Adding messages to a queue
You can find the following demo on GitHub.
- Create a new C# console application.
- Add the following code to your app.config file:
Setup the connection string to your storage account
Replace the placeholder with your storage account name and storage account key.
- Install the WindowsAzure.Storage NuGet package.
- In the Main method, retrieve the connection string:
Retrieve the connection string
- You can create a queue with the following code:

Create the queue queue if it does not exist
- After the queue is created, add messages to it:

Add three messages to the queue
- In the Azure Portal, open your storage account and select Queues on the Overview blade. There, you can see your newly created queue and the three added messages.
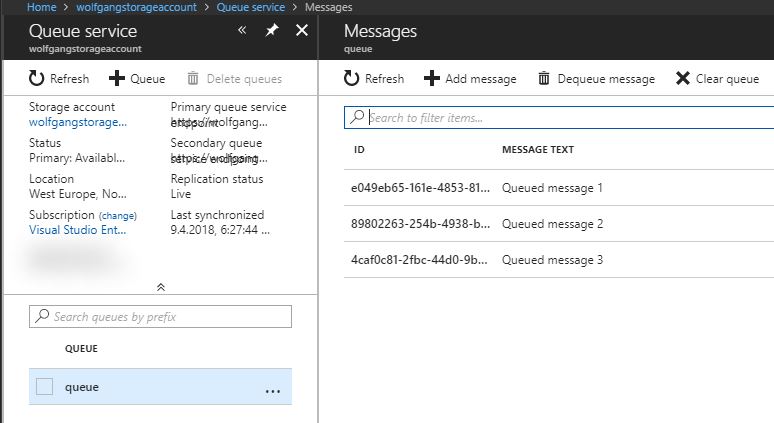
On the screenshot above, you can see that every message in the queue got a unique ID assigned. This ID is used by the Storage Client Library to identify a message.
The maximum size for a message in a queue is 64 KB, but it is best practice to keep the messages as small as possible and to store any required data for processing in a durable store, such as Azure SQL or Azure Storage tables. The Azure Storage Queue can store messages up to seven days.
Processing messages
Messages are usually published by a different application from the application that listens for new messages to process them. For simplicity, I use the same application for publishing and listening in this demo. To de-queue a message use the following code:
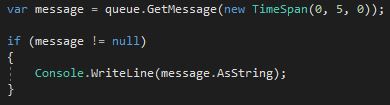
Dequeue a single message from the queue which is not older than five minutes
The code returns the oldest message, which is not older than five minutes.
Retrieving a batch of messages
A queue listener can be implemented as single-threaded (processing one message at a time) or multi-threaded (processing messages in a batch on separate threads). You can retrieve up to 32 messages from a queue using GetMessages() to process multiple messages in parallel. To get more than one message with GetMessages(), specify the number of items which should be de-queued:
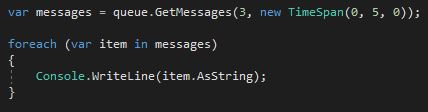
Dequeue multiple messages from the queue
Consider the overhead of message processing before deciding the appropriate number of messages to process in parallel. If significant memory, disk space, or other network resources are used during processing, throttling parallel processing to an acceptable number will be necessary to avoid performance degradation on the compute instance.
Scaling queues
Each individual queue has a target of approximately 20,000 messages per second. You can partition your application to use multiple queues to increase this throughput.
It is more cost-effective and efficient to pull multiple messages from the queue for processing in parallel on a single compute node. However, this depends on the type of processing and resources required. Scaling out compute nodes to increase processing throughput is usually also required.
You can configure VMs or cloud services to auto-scale by queue. You can specify the average number of messages to be processed per instance, and the auto-scale algorithm will queue to run scale actions to increase or decrease available instances accordingly.
Choose between Azure Storage Tables and Azure Cosmos DB Table API
Azure Cosmos DB is a cloud-hosted, NoSQL database. A NoSQL database can be key/value stores, table stores, and graph stores. Azure Cosmos DB Table API is a key value store that is very similar to Azure Storage Tables.
The main differences are:
- Azure Table Storage only supports a single region with one optional secondary for high availability. Cosmos DB supports over 30 regions.
- Azure Table Storage only indexes the partition and the row key. Cosmos DB automatically indexes all properties.
- Azure Cosmos DB is much faster, with latency lower than 10 ms on reads and 15 ms on writes at any scale.
- Azure Table Storage only supports strong or eventual consistency. Stronger consistency means less overall throughput and concurrent performance while having more up to date data. Eventual consistency allows for high concurrent throughput but you might see older data. Azure Cosmos DB supports five different consistency models and allows those models to be specified at the session level. This means that on user or feature might have a different consistency level than a different user or feature.
- Azure Table Storage only charges for the storage you use. This makes it very affordable. Azure Cosmos DB on the other side charges for Request Units (RU) which really is a way for a PaaS product to charge for computer fees. If you need more RUs, you can scale them up. This makes Cosmos DB significantly more expensive than Azure Storage Tables.
Conclusion
In this post, I talked about how to use Azure Storage Tables and Azure Storage Queues. I showed how to programmatically access both and how to add, retrieve, and remove data. Then, I talked about how to scale Azure Storage Tables and Azure Storage Queues. The last section was a comparison between Azure Storage Tables and Azure Cosmos DB.
You can find the demo code for the Azure Storage Table here and the demo code for the Azure Storage Queues here.
For more information about the 70-532 exam get the Exam Ref book from Microsoft and continue reading my blog posts. I am covering all topics needed to pass the exam. You can find an overview of all posts related to the 70-532 exam here.
Comments powered by Disqus.